一.HashMap的原理
1.HashMap内部结构
HashMap底层就是一个数组,结合链表和红黑树来解决冲突。无论有没有哈希冲突,数组桶里永远只存“指向节点的引用(箭头)”,节点对象本身(包含 key、value、next)存在堆内存中。
// HashMap底层数组
Node<K,V>[] table;
// 假设桶下标 3 只有一个节点
Node<String,Integer> node = new Node<>("苹果", 5, null);
table[3] = node; // 桶里存这个节点的引用
System.out.println(node.next); // 输出 null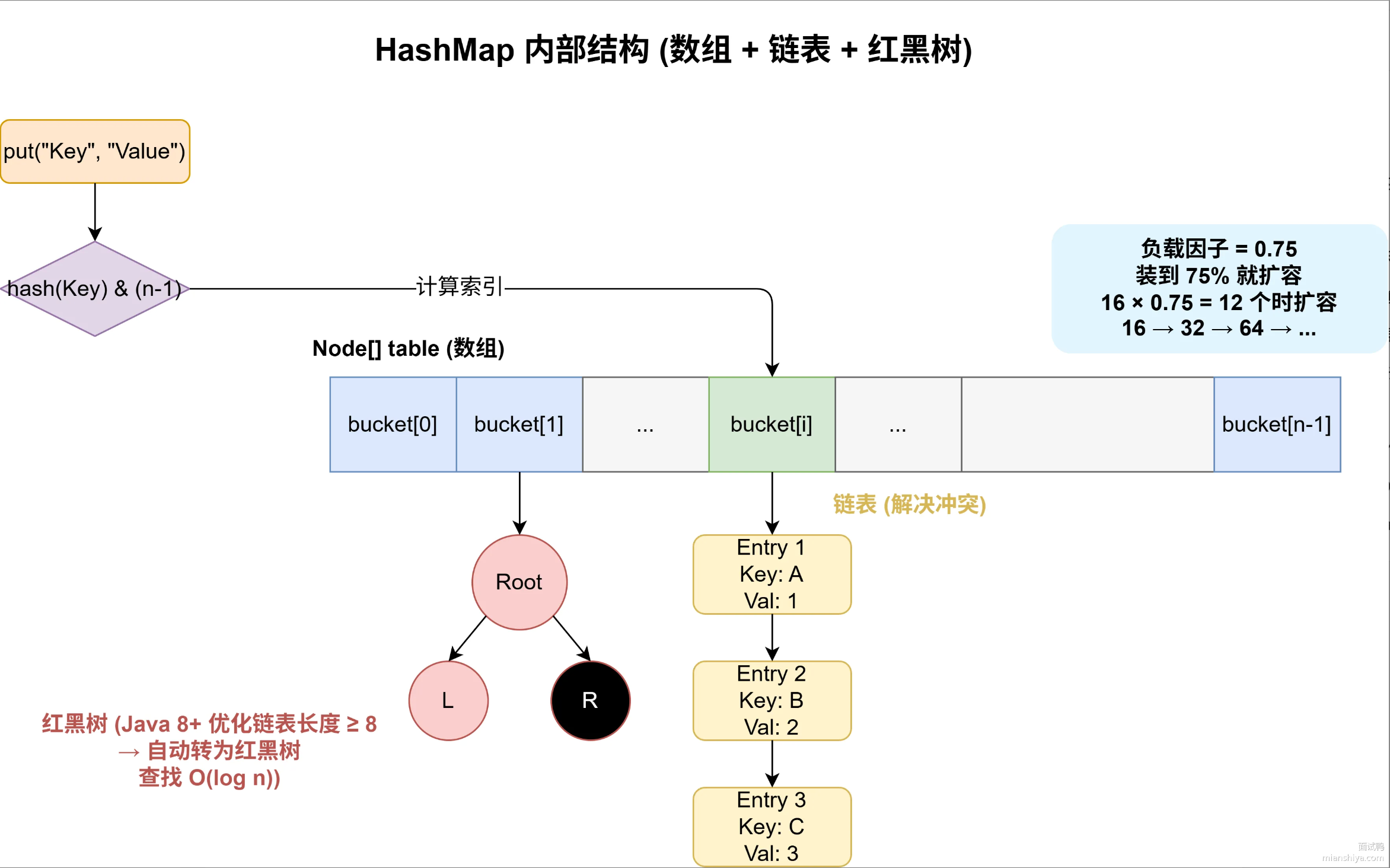
2.Java 中 HashMap 的链表节点(Node)
static class Node<K,V> {
final int hash;
final K key; // 自己的名字(当前节点的标识)
V value; // 自己的数据
Node<K,V> next; // 这就是“纸条”,写下一个人的名字
}其中next 就是“下一个节点对象的地址”(在 Java 里叫“对象引用”)。
3.当同一个数组桶里需要使用链表时,JDK 1.7采用头插法,JDK 1.8+采用尾插法。
(1)头插法(JDK 1.7)
原链表:table[3] → 苹果( next → 香蕉( next → null ) )
插入新节点“橙子”:
创建新节点
橙子,它的next指向当前头节点苹果。然后
table[3] = 橙子。结果链表:
橙子 → 苹果 → 香蕉 → null苹果的
next没有变,仍然指向香蕉。
所以“苹果”的
next不需要重新赋值。
(2)尾插法(JDK 1.8+)
原链表:table[3] → 苹果( next → 香蕉( next → null ) )
插入新节点“橙子”:
遍历到链表尾部(香蕉节点),发现
香蕉.next == null。创建新节点
橙子,橙子.next = null。将
香蕉.next = 橙子。结果链表:
苹果 → 香蕉 → 橙子 → null尾节点(香蕉)的
next被重新赋值为橙子。
如果原链表只有一个节点“苹果”(苹果.next == null),那么苹果的next会被重新赋值为橙子。
二、ConcurrentHashMap
HashMap本身是非线程安全的,并发put的时候容易丢数据,2个线程同时往同一个空桶里插入,后插入的会覆盖先插入的,多线程场景必须用ConcurrentHashMap。
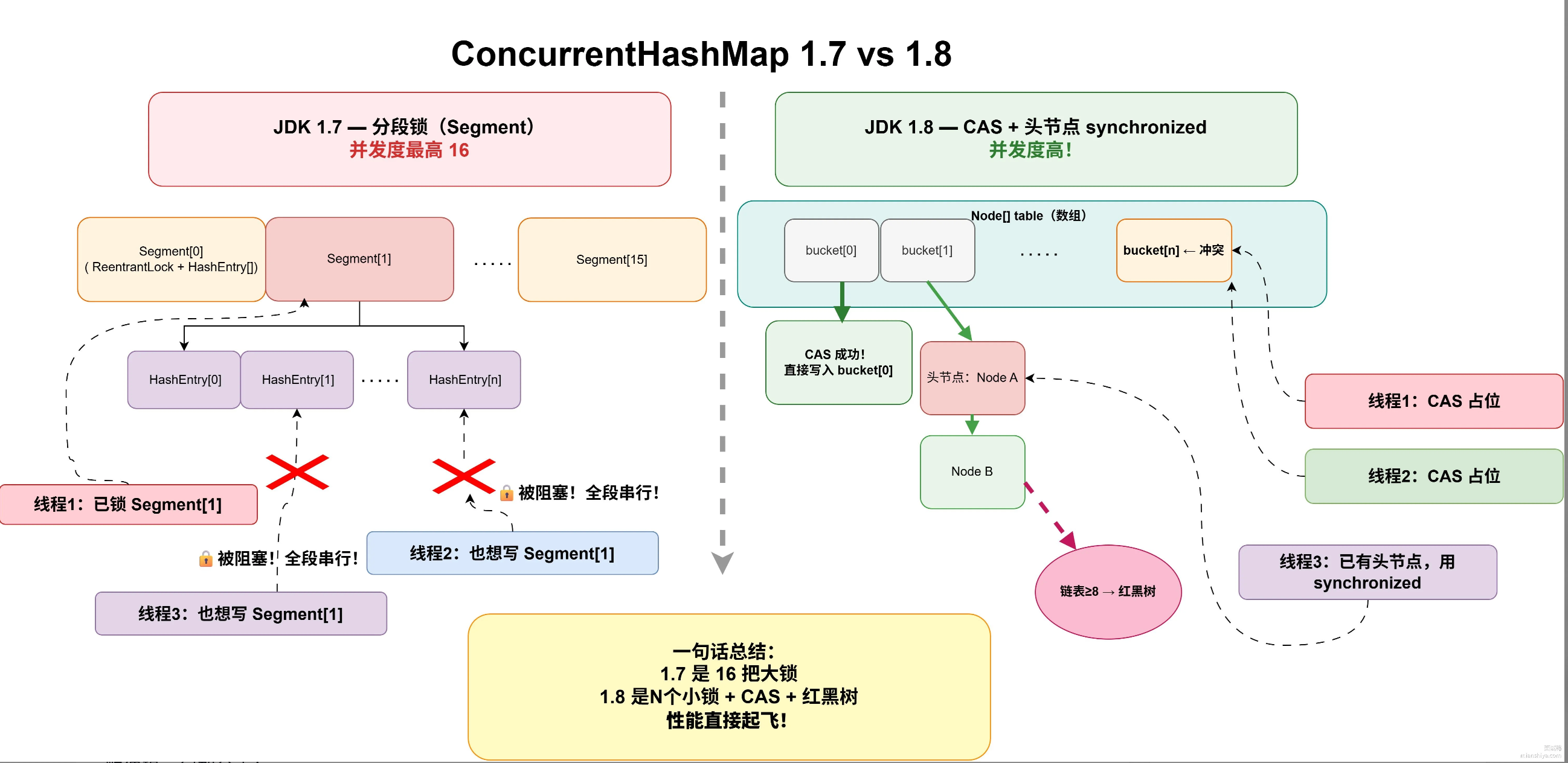
ConcurrentHashMap1.7和1.8核心区别如下
1. 核心设计与数据结构
JDK 1.7:分段锁
它将整个数据集合分成多个小的数据段(Segment),每个Segment内部持有自己的数组+链表结构,且继承自ReentrantLock,自己就是一把锁。写操作时,只需锁住对应的
Segment,不同Segment的数据可以被其他线程并发访问,从而提升效率。但并发度受限于Segment的初始数量(默认16),之后无法改变。JDK 1.8:CAS + Synchronized
它放弃了Segment的设计,结构上与 JDK 1.8 的HashMap类似,使用一个Node数组。在并发控制上,采用了更细粒度的锁:当数组的某个位置为空时,优先使用 CAS 操作进行无锁插入。
当该位置已有节点(发生哈希冲突)时,则使用
synchronized锁住该位置的链表或红黑树头节点。这样,锁的范围从一大段数据缩小到了单个桶,并发度得到巨大提升。
2. 写操作 (put) 流程
JDK 1.7:首先定位到具体的
Segment并获取其锁,然后在该Segment内部进一步定位到具体的HashEntry位置,再进行插入或更新操作。JDK 1.8:
根据
key的哈希值定位到Node数组的索引i。若
table[i]为null,则通过 CAS 尝试将新节点放入,成功则结束。若
table[i]不为null,则用synchronized锁住table[i]这个头节点,再判断是链表还是红黑树,并进行插入或更新。
3. 扩容机制 (resize)
JDK 1.7:扩容是针对单个
Segment的,且由执行put的线程单枪匹马完成。JDK 1.8:支持多线程并发扩容。当一个线程发现需要扩容时,会协助进行数据迁移,其他线程在
put时如果检测到当前桶正在扩容,也会参与其中,大大加快了扩容速度。
4. 统计元素个数 (size)
JDK 1.7:会先尝试两次不加锁地统计所有
Segment的count。如果两次结果不一致,说明有并发修改,才会锁住所有Segment进行精确统计,开销较大。JDK 1.8:使用一个
baseCount变量配合CounterCell数组来维护元素个数。size()方法就是简单地累加这些值,无需加锁,性能更好。